An Introduction to Lock-Free Programming
락 프리 프로그래밍은 그 자체가 복잡하기도 하지만 애초에 이 주제를 이해하기조차 힘들기 때문에 아주 도전적이다.
What Is It?
락 프리 프로그래밍을 뮤텍스(락) 없이 프로그래밍하는 거라고 말하는 사람들이 있다. 맞는 말이긴 한데, 이건 일부분일 뿐이다. 학계에서 일반적으로 동의하는 정의는 좀더 넓다. 본질적으로 락 프리는 어떤 코드가 실제로 어떻게 작성됐는지에 대해서 너무 많이 얘기하지 않으면서 그 코드를 설명하기 위한 속성이다.
기본적으로 프로그램의 일부분이 다음과 같은 조건을 만족하면, 그 부분은 락 프리로 여겨진다. 반대로, 코드의 일부분이 아래 조건을 만족하지 못한다면, 그 부분은 락 프리가 아니다.
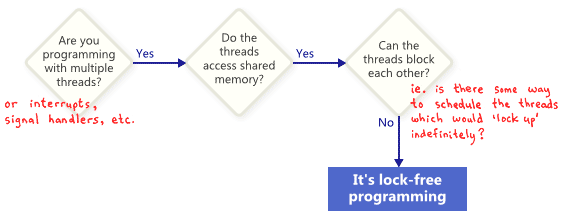
요약하면:
- 여러 개의 쓰레드 또는 인터럽트 또는 시그널 핸들러가 존재하고,
- 쓰레드끼리 메모리를 공유하고,
- 쓰레드끼리 서로 블록하지 않으면,
락 프리이다.
이런 관점에서, 락 프리의 락은 직접적으로 뮤텍스를 가리키는 말이 아니라, 전체 어플리케이션을 어떤 방식으로든 “잠궈버리는(locking up)” 가능성을 가리킨다. 예를 들어서 데드락, 라이브 락, 또는 최악의 가정 하에 어떤 가상의 쓰레드 스케쥴링 때문에 발생했든 상관없다.
뮤텍스가 없고 락 프리가 아닌 단순한 예제 코드는 다음과 같다.
while (X == 0)
{
X = 1 - X;
}
커다란 어플리케이션 전체가 락 프리일거라고는 아무도 예상하지
않는다. 보통 전체 코드 베이스에서 구체적인 락 프리 연산을
확인한다. 예를 들면, 락 프리 큐에서는 push, pop, isEmpty와 같은
락 프리 연산이 있을 수 있다.
프로그램이 이런 락 프리 연산을 호출하는 것을 유지하기만 한다면, 완료된 호출의 수는 계속 늘어날 것이다.
락 프리 프로그래밍의 중요한 점 중 하나는, 만약 쓰레드 하나를 중지하면, 다른 쓰레드가 락 프리 연산을 통해 그룹으로 연산을 계속 진행하는 걸 막을 수 없다는 점이다. 그러므로 프로그램의 나머지 상태와 관계없이 특정 작업이 특정 시간 제한 이내에 완료되어야 하는 인터럽트 핸들러나 실시간 시스템을 작성할 때 락 프리 프로그래밍은 가치 있다.
마지막으로, 블록하도록 디자인된 연산이 락 프리 알고리즘을 깨진
않는다. 예를 들어, 큐가 비었을 때 큐의 pop 연산이 의도적으로 블록할
수 있다. 나머지 코드 경로는 여전히 락 프리로 여겨진다.
Lock-Free Programming Techniques
락 프리 프로그래밍의 논 블로킹 조건을 만족시킬 수 있는 기술은 다음과 같다: 아토믹 연산, 메모리 배리어, ABA 문제 피하기, 등. 여기서부터 사악해진다.
이 기술들이 서로 어떤 관계를 가질까? 다음 플로우 차트를 보자.
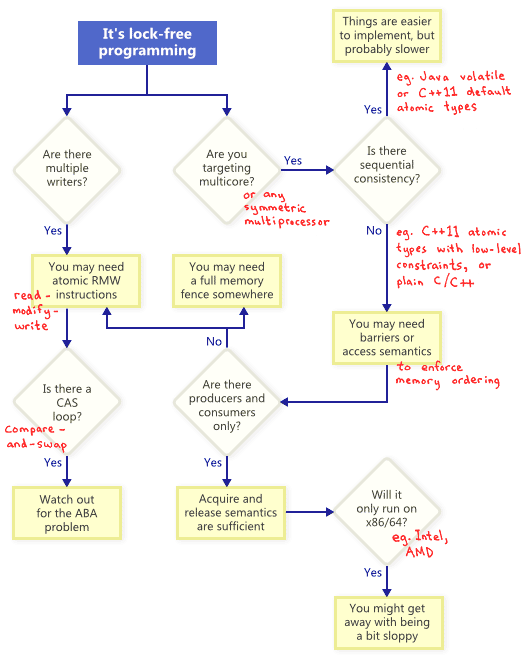
- RMW(Read-Modify-Write) 인스트럭션
- 메모리 펜스
- CAS(Compare-and-Swap)와 ABA 문제 피하기
- (메모리 순서를 강제하기 위한) 메모리 배리어 또는 Acquire and Release semantics
volatile또는 아토믹 타입을 이용한 sequential consistency
Atomic Read-Modify-Write Operations
아토믹 연산이란 나눌 수 없는 방식으로로 메모리를 조작하는 연산이다. 어떤 쓰레드도 연산이 반만 완료된 상태를 볼 수 없다. 현대 프로세서에서는 많은 연산이 이미 아토믹이다. 예를 들면, 단순 타입의 정렬된 읽기와 쓰기은 대부분 아토믹이다.
읽고-수정하고-쓰기 (RMW) 연산은 여기서 한 단계 더 나아가서, 더 복잡한 연산을 아토믹하게 수행할 수 있게 해준다. 특히 락 프리 알고리즘이 데이터를 쓰는 쓰레드를 여러 개 지원해야 할 때 유용한데, 여러 개의 쓰레드가 같은 주소에 대해서 RMW를 시도하려고 하면 이 시도를 효과적으로 한 줄로 새워서 한 번에 하나 씩 실행하기 때문이다.
RMW 연산의 예시로는 Win32의 _InterlockedIncrement, iOS의
OSAtomicAdd32, C++11의 std::atomic<int>fetch_add 등이
있다. C++11의 아토믹 표준은 모든 플랫폼에서 락 프리를 보장하지 않기
때문에, 사용할 플랫폼과 툴체인이 뭘 지원하는지를 미리 알아두는게
좋다. std::atomic<>::is_lock_free로 확인해볼 수도 있다.
CPU 제조사들은 서로 다른 방법으로 RMW를 지원한다. PowerPC나 ARM같은 프로세서는 load-link/store-conditional 인스트럭션을 제공하는데, 저수준에서 직접 RMW 프리미티브 연산을 구현할 수 있는 효과적인 방법이다.
위의 플로우 차트에서 보듯이, 싱글 프로세서 시스템에서 조차 아토믹 RMW은 락 프리 프로그래밍을 위해서 필요한 부분이다. 아토믹 연산이 없다면, 쓰레드는 트랜잭션 도중에 인터럽트 되어 일관되지 않은 상태가 될 수 있다.
Compare-And-Swap Loops
아마 가장 자주 논의되는 RMW 연산은 CAS 연산일 것이다. Win32에서 CAS는
_InterlockedCompareExchange 같은 인트린직 연산으로 제공된다. 종종
프로그래머는 반복적으로 트랜잭션을 시도하는 루프로 CAS를
수행한다. 이런 패턴은 보통 공유 변수에서 지역 변수로 값을 복사한
다음, 뭔가 투기적인 작업을 하고, CAS를 이용해 최종 변화를 덮어쓰려는
시도를 한다.
void LockFreeQueue::push(Node* newHead)
{
for (;;)
{
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
}
}
하나의 쓰레드가 테스트에 실패한다면 다른 쓰레드는 반드시 성공해야 한다는 것을 뜻하기 때문에, 이런 루프는 여전히 락 프리 성질을 만족한다. 하지만 몇몇 아키텍쳐에서는 좀더 약간 CAS의 변형을 제공하기도 하는데 이 경우는 반드시 만족하진 않는다. CAS 루프를 구현할 때에는 항상 ABA 문제를 피하기 위해서 주의를 기울여야 한다.
Sequential Consistency
순차적 일관성(Sequential consistency)이란 메모리 연산이 어떤 순서로 발생해야 하는지에 대해서 모든 쓰레드가 동의하고 그 순서가 프로그램의 소스 코드에 적힌 연산의 순서와도 일관된다는 것을 뜻한다. 순차적 일관성 하에서는 메모리 연산 순서가 뒤바뀌는 속임수는 불가능하다.
순차적 일관성을 얻기 위한 간단(하지만 명백히 비현실적인)한 방법은 모든 컴파일러 최적화를 꺼버리고 모든 쓰레드가 싱글 쓰레드에서만 동작하도록 강제하는 것이다. 프로세서는 어떤 쓰레드가 선점되어서 임의의 시간에 스케쥴링 된다 하더라도 절대로 메모리 연산 순서가 꼬이는 것을 볼 수 없다.
몇몇 프로그래밍 언어는 멀티 프로세서 환경에서 동작하는 최적화된
코드에 대해서도 순차적 일관성을 제공한다. C++11에서는 모든 공유
변수를 디폴트 메모리 오더링 제약을 갖는 C++11 아토믹 타입으로
선언하면 된다. 자바에서는 모든 공유 변수를 volatile로 선언하면
된다.
std::atomic<int> X(0), Y(0);
int r1, r2;
void thread1()
{
X.store(1);
r1 = Y.load();
}
void thread2()
{
Y.store(1);
r2 = X.load();
}
C++11 아토믹 타입이 순차적 일관성을 보장하기 때문에, r1 = r2 = 0은
불가능하다. 이걸 위해서 컴파일러는 눈에 보이지 않는 추가적인 명령어를
끼워넣는데, 보통 메모리 펜스와/또는 RMW 연산이다. 이런 추가적인
명령어는 프로그래머가 직접 메모리 오더링을 관리하는 것과 비교해서
구현의 성능을 떨어뜨릴 수 있다.
Memory Ordering
플로우차트에서 보듯이, 멀티코어에서 락 프리 프로그래밍을 할 때마다, 그리고 순차적 일관성을 보장하지 않는다면, 메모리 순서가 바뀌는 것을 막는 방법을 고려해야만 한다.
현대 아키텍쳐에서, 올바른 메모리 오더링을 강제하기 위한 도구는 보통 세 가지 종류로 나뉜다. 이 방법은 컴파일러 리오더링과 프로세서 리오더링을 모두 막는다.
- 가벼운 동기화 또는 펜스 인스트럭션
- 전체 메모리 펜스 인스트럭션
- acquire/release 시맨틱을 제공하는 메모리 연산
Acquire 시맨틱은 프로그램에 순서 뒤에 오는 연산의 메모리 리오더링을 막고, release 시맨틱은 순서 앞에 오는 메모리 리오더링을 막는다. 이 시맨틱은 하나의 쓰레드가 어떤 정보를 생산하고 다른 여러 쓰레드가 이것을 읽는 생산자/소비자 관계에서 특히 적절하다.
Different Processors Have Different Memory Models
서로 다른 CPU는 메모리 리오더링과 관련해서 서로 다른 행동을 한다. 그 규칙은 CPU 벤더가 문서화 해두었고 하드웨어가 엄격하게 지킨다. 예를 들면 PowerPC와 ARM 프로세서는 명령어 자체와 관련된 메모리 저장(store) 연산의 순서를 바꿀 수 있지만, 일반적으로 인텔 및 AMD의 x86/64 프로세서 제품군은 그렇지 않다. 전자를 좀더 너그러운 메모리 모델을 갖고 있다고 말한다.
특히 C++11가 제공하는 포터블한 락 프리 코드를 작성할 수 있게 해주는 표준적인 방식처럼, 이런 플랫품 특화 디테일을 추상화해버리고 싶은 유혹이 있을 것이다. 하지만 현재, 대부분의 락 프리 프로그래머는 플랫폼 별로 차이가 있다는 사실에 약간 감사하고 있는 것 같다. 한 가지 핵심 차이점은, x86/64 인스트럭션 레벨에서, 메모리에서 값을 읽는(load) 모든 연산은 acquire 시맨틱을 갖고, 모든 저장(store) 연산은 release 시맨틱을 갖는다는 것이다. 최소한 SSE가 아닌 인스트럭션과 non-write-combined 메모리에 한해서는 그렇다. 결과적으로, 과거에는 x86/64에서는 잘 동작하지만 다른 프로세서에서는 그렇지 못한 락 프리 코드가 작성되는 것이 일반적이었다.