가비지 콜렉터의 이해
프로그램을 실행하면 OCaml이 할당된 값을 주기적으로 살펴보고 더 이상 필요없으면 해제해줘서 변수의 라이프 싸이클을 관리해준다. 이 뜻은 결국 프로그램이 메모리 관리를 직접 구현할 필요가 없다는 뜻이고, 살금살금 기어 들어오는 메모리 관련 오류의 가능성을 엄청나게 낮춰준다는 뜻이다.
OCaml 런타임은 실행 중인 OCaml 프로그램이 호출할 수 있는 루틴을 제공하는 C 라이브러리이다. 런타임은 운영체제로부터 획득한 메모리 구역의 집합인 힙을 관리한다. 런타임은 이 메모리를 이용해 힙 블록을 유지하여 OCaml 프로그램이 요청한 할당에 대응하여 OCaml 값을 채워넣는다.
이 이후에는 가비지 콜렉션, 가비지 콜렉터, GC 용어를 섞어 쓴다.
마크 & 스윕 GC
미리 할당해놓은 힙 블록 풀만으로는 메모리가 부족할 때, 런타임 시스템은 GC를 부른다. OCaml 프로그램은 일을 다 하고 나서 명시적으로 어떤 값을 해제할 수 없다. 대신, GC가 정기적으로 어떤 값이 살아있고(live) 어떤 값이 죽었는지(dead), 즉 더 이상 안쓰는지를 판별한다. 죽은 값은 수집되고 그 값을 담던 메모리는 재사용을 위해서 쓰인다.
GC는 어떤 값이 할당되고 사용되는지를 계속 추적하고 있지 않는다. 대신,
스택처럼 어플리케이션이 항상 접근할 수 있는 이른바 루트(root) 값의
집합으로부터 시작해서 정기적으로 훑어본다. GC는 힙 블록이 노드이고,
힙 블록 b1이 힙 블록 b2를 가리키는 포인터일 때 b1 -> b2로
엣지가 있는 방향 그래프를 유지한다.
루트에서 그래프의 엣지를 따라 닿을 수 있는 모든 블록은 사용 중이므로 그대로 남아있어야 한다. 닿을 수 없는 블록은 어플리케이션이 재사용할 수 있어야 한다. OCaml이 힙 탐색에 사용하는 알고리즘은 잘 알려진 마크 & 스윕 가비지 콜렉션이다.
세대 간 GC
보통의 프로그래밍 스타일은 수많은 작은 변수를 할당해서 짧은 기간 동안만 사용하고 다시는 접근하지 않는다. OCaml은 이 사실을 활용해서 GC의 성능을 끌어올리는데, 이를 세대 간(generational) GC라고 한다.
세대 간 GC는 블록이 얼마나 살아있었는지에 따라 분리된 메모리 구역을 유지한다. OCaml은 두 개의 구역으로 나뉜다.
- 작고, 고정된 크기의 마이너 힙. 대부분의 블록이 처음에 할당된다.
- 더 크고, 가변 크기의 메이저 힙. 더 오래 살아남은 블록이 할당된다.
전형적인 함수형 프로그래밍 스타일에 따르면, 어린 블록은 일찍 죽는 편이며 늙은 블록은 어린 것보다 훨씬 더 오래 머무른다고 한다. 이는 세대 간 가설(generational hypothesis)이라고 불리기도 한다.
OCaml은 메이저와 마이너 힙에 따라 메모리 레이아웃과 GC 알고리즘을 다르게 쓴다.
GC 모듈과 OCAMLRUNPARAM
OCaml은 런타임 시스템의 동작을 묻고 변경하는 몇 가지 메커니즘을
제공한다. Gc 모듈은 OCaml 코드 안에서 이런 기능을 제공한다.
프로그램을 시작하기 전에 OCAMLRUNPARAM 환경 변수를 조절해서 OCaml
프로그램의 동작을 조절할 수도 있다. 프로그램을 다시 컴파일 하지
않아도 GC 파라미터를 조절할 수 있다. 자세한 건 매뉴얼에 적혀있음.
빠른 마이너 힙
마이너 힙은 단명하는 대부분의 값을 담아두는 곳이다. 하나의 연속된 가상 메모리 덩어리 안에 OCaml 블록의 배열이 담겨 있다. 남는 공간이 있으면 새 블록을 할당하는 일은 아주 빠른 상수 시간의 연산으로 고작 몇 개의 CPU 명령어를 필요로 한다.
마이너 힙을 GC 하기 위해서 OCaml은 복사 수집(copying collection)
이라는 방법을 쓴다. 마이너 힙에 살아있는 모든 블록을 메이저 힙으로
옮기는 것(이를 oldify라고 함)이다. 이 작업은 마이너 힙에 살아있는
블록의 수에 비례한 시간이 걸리는데, 세대 간 가설에 따라 보통
적다. 마이너 수집은 또 중단 수집(stop-the-world)이기도 한데, 마이너
수집을 하는 동안 어플리케이션이 멈춘다. 따라서, 최소한의 방해만 하기
위해서 빠르게 수집을 끝내고 어플리케이션을 다시 시작하는 것이 아주
중요하다.
마이너 힙에 할당하기
마이너 힙은 보통 수 메가바이트 정도의 크기를 가져서 아주 빠르게 훑어볼 수 있는 가상 메모리의 연속된 덩어리다.
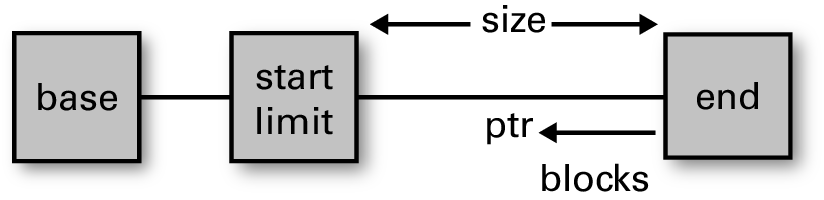
런타임은 마이너 힙의 경계를 두 개의 포인터에 저장하는데, 이는 각각 힙
구역의 시작과 끝을 구분한다. 이 두 포인터는 caml_young_start와
caml_young_end인데, 여기서는 축약을 위해서 caml_young 접두사를
뺐다. base(즉, caml_young_base)는 시스템 malloc이 리턴하는
메모리 주소이고, start는 OCaml 값을 더 쉽게 저장하기 위해서
base로부터 다음으로 가장 가까운 워드 경계에 맞춰진다.
신선한(?) 마이너 힙에서는 limit가 start와 같고 현재 ptr은
end와 같다. 블록이 할당되면 ptr은 계속 줄어들다가 limit에 닿는
순간 마이너 GC의 방아쇠를 당긴다.
마이너 힙에서 블록 하나를 할당하는 일은 그냥 ptr을 (헤더를 포함한)
블록 크기만큼 줄이고 limit보다 작은지를 체크하는
일이다. limit보다 작게 ptr을 줄여여 블록을 위한 공간을 할당할 수
있을 때, 마이너 GC가 시작된다. 이것은 대부분의 CPU 아키텍쳐에서
브랜치가 필요없는 아주 빠른 체크이다.
할당의 이해
어차피 start랑 같은 값인데 왜 limit이 필요한지 궁금할 수 있다. 그
이유는 바로 런타임이 마이너 힙 수집을 스케쥴링하기 위한 가장 쉬운
방법이 바로 limit을 end로 세팅하는 것이기 때문이다. 이러고 나면
그 다음 할당은 절대로 충분한 공간을 가질 수 없고 항상 GC가
시작된다. 이런 이른 수집에는 아직 끝나지 않은 유닉스 시그널을 다룰 때
쓰이거나 하는 다양한 내부 사정이 있는데, 일반적인 어플리케이션
코드에서는 신경쓰지 않아도 된다.
마이너 힙 크기 설정하기
마이너 힙의 기본 크기는 64비트 플랫폼에서 2 MB이지만, Core
라이브러리에서는 8 MB이다. 이 설정은 OCAMLRUNPARAM 환경변수에
s=<words>를 넘겨줘서 덮어쓸 수 있다. 또는 아래와 같이 Gc.tune
함수를 호출해서 설정할 수도 있다.
open Core
Gc.tune ~minor_heap_size:(262144 * 2) ();;
GC 크기를 동적으로 바꾸는 순간 바로 마이너 힙 수집이
시작된다. Core가 기본 마이너 힙 크기를 표준 OCaml에 비해 상당히
증가시키기 때문에 메모리가 아주 제한된 환경에서는 줄이는게 좋다.
장수하는 메이저 힙
메이저 힙은 오래 살고 더 큰 값의 대부분이 저장되는 곳이다. 임의의 수의 비연속적인 가상 메모리 덩어리로 구성되고, 각각은 여기저기 살아있는 블록을 담고 있다. 런타임은 시스템은 이때까지 할당한 모든 여유 메모리를 인덱싱하는 미사용 리스트(free-list) 데이터 구조를 유지하는데, 이를 이용해서 OCaml 블록 할당 요청을 들어준다.
메이저 힙은 보통 마이너 힙보다 훨씬 더 크고 기가바이트 단위의 요청도 들어줄 수 있다. 메이저 힙에서의 수집은 마크 & 스윕 알고리즘을 이용하며 다음과 같은 단계를 갖는다.
- 마크(mark) 단계에서는 블록 그래프를 훑으면서 블록 헤더의 색깔(color) 태그 비트를 설정하여 모든 살아있는 블록을 표시(마크)한다.
- 스윕(sweep) 단계에서는 순차적으로 힙 덩어리를 훑어보고 이전에 마크되지 않은 죽은 블록을 식별한다.
- 압축(compact) 단계에서는 살아있는 블록을 새로 할당된 힙으로 재배치해서 미사용 리스트의 간격을 제거한다. 이는 오랫동안 동작하는 프로그램에서 힙 블록의 파편화(fragmentation)를 방지한다. 보통 마크 & 스윕 단계보다 훨씬 덜 자주 일어난다.
메이저 가비지 콜렉션 역시 GC가 힙 블록을 움직이는 것을 프로그램이 관찰하지 못하도록 하기 위해서 반드시 프로그램을 멈춰야 한다(stop-the-world). 마크 & 스윕 단계는 점진적으로(incrementally) 동작하는데 이 단위를 힙 조각(slices of the heap)이라고 하며, 어플리케이션을 장기간 멈추는 것을 피하게 해준다. 그리고 각각의 힙 조각을 처리하기 전에 빠른 마이너 수집을 먼저 한다. 전체 메모리를 한번에 건드리는 것은 압축 단계 뿐인데, 이는 상대적으로 드문 작업이다.
메이저 힙에 할당하기
메이저 힙은 연속된 메모리 덩어리가 노드인 싱글 링크드 리스트로
구성되어 있고, 가상 메모리 주소가 증가하는 순서로 정렬되어
있다. 각각의 덩어리는 malloc(3)으로 할당된 하나의 메모리 구역이며
헤더와 OCaml 힙 덩어리를 담은 데이터 영역으로 구성된다. 힙 덩어리
헤더는 다음을 담고 있다:
malloc으로 할당된 메모리 구역의 가상 메모리 주소- 데이터 영역의 크기 (바이트)
- 힙을 조각 모음하기 위해서 작은 블록을 병합하는 힙 압축 동안 사용되는 할당 크기 (바이트)
- 리스트의 다음 힙 덩어리로 가는 링크(포인터)
- 블록의 시작과 끝 범위를 가리키는 포인터. 아직 확인되지 않은 필드가 담겨있을 수 있어서 나중에 훑어 볼 필요가 있다. 마크 스택 오버플로우 이후에만 쓰인다.
각 덩어리의 데이터 영역은 페이지 범위에서 시작하고, 그 크기는 페이지 사이즈인 4KB의 배수이다. 여기에는 하나 또는 두 개의 4KB 페이지 정도로 작은 힙 블록의 연속된 배열을 담고 있지만, 보통 1MB 덩어리(또는 32비트 아키텍쳐에서는 512KB)에 할당되어 있다.
메이저 힙 성장 조절
Gc 모듈은 major_heap_increment 값을 이용해서 메이저 힙의 성장을
조절한다. 이 값은 확장할 때마다 메이저 힙에 추가할 워드의 개수를
정의하는데, 이는 프로그램 시작 이후 OCaml 런타임으로부터 운영체제가
관찰하는 단 하나의 메모리 할당 작업이다.
만약 한번에 엄청 큰 OCaml 값을 할당하거나 아니면 작은 값을 굉장히 많이 할당할 걸로 예상되면, 힙 증가분을 더 큰 값으로 잡음으로써 할당 요청을 만족시키기 위해 힙 사이즈를 조절하는 횟수를 줄여 성능을 향상시킬 수 있다. 만약 증가분이 작으면 가상 메모리의 여러 다른 구역에 흩뿌려져서 작은 힙 덩어리를 엄청 많이 할당하게 되고, 이러면 OCaml 런타임이 이를 추적하기 위해서 더 많은 작업을 해야한다.
Gc.tune ~major_heap_increment:(100448 * 4) ();;
OCaml 값을 메이저 힙에 할당하려면 먼저 값을 할당할 만한 적절한 구역이 있는지 미사용 리스트를 체크한다. 미사용 리스트에 충분한 공간이 없으면, 런타임은 충분히 큰 새로운 힙 덩어리를 할당하여 메이저 힙을 확장한다. 이 덩어리는 미사용 리스트에 추가되고, 그 다음 다시 한번 미사용 리스트를 체크한다. 이때는 분명 성공할 것이다.
대부분의 메이저 힙 할당은 마이너 힙을 통해 이뤄지며 마이너 수집 이후에도 여전히 프로그램이 사용하는 (살아있는) 경우에만 승격(promote; oldify)된다는 것을 기억하자. 단, 값의 크기가 256 워드보다 클 때, 즉 64비트 플랫폼에서 2KB 이상일 때에는 예외이다. 이때는 마이너 힙에 할당하면 어차피 곧바로 수집이 일어나서 메이저 힙으로 복사될 것이기 때문이다.
메모리 할당 전략
메이저 힙은 메모리 할당을 최대한 효울적으로 하기 위해서 최선을 다하고, 메모리가 연속적이며 파편화되지 않도록 하기 위해서 힙 압축에 의존한다. 디폴트 할당 전략은 보통 대부분의 어플리케이션에서 잘 동작하지만, 다른 옵션도 있다는 걸 알아두면 좋다.
메이저 힙에 새로운 블록을 할당할 때에는 언제나 미사용 리스트를 먼저 확인한다. 기본적인 미사용 리스트 탐색은 최적 할당(best-fit allocation)이고, 다른 옵션으로 다음 할당(next-fit)과 처음 할당(first-fit)이 가능하다.
최적 할당
최적 할당은 두 전략의 조합이다. 먼저, 크기 별로 분리된(size-segregated) 미사용 리스트는 거의 모든 메이저 힙 할당의 크기가 작다는 관찰에 근거한다. 최적 할당은 대부분의 할당에 대해서 빠른 경로를 제공하는 최대 16 워드를 포함하는 크기에 대해 별도의 미사용 리스트를 유지한다. 이 크기에 대한 할당은 각 크기 별로 분리된 미사용 리스트에서 꺼내올 수도 있고, 아니면 리스트가 빈 경우 그 다음 크기의 리스트에서 꺼내올 수도 있다.
두 번째 전략은 더 큰 크기의 할당에 대한 것으로, 스플레이 트리(splay tree)라는 특별한 데이터 구조를 미사용 리스트에 이용한다. 이것은 검색 트리의 일종으로, 최근에 접근하는 패턴에 적응한다. 즉, 가장 일반적인 할당 요청 크기는 가장 빠르게 접근할 수 있다는 뜻이다.
크기 별로 분리된 미사용 리스트에 더 큰 크기의 블록이 없을 때의 작은 크기에 대한 할당과 16 워드보다 더 큰 사이즈의 할당은 메인 미사용 리스트에서 꺼내온다. 미사용 리스트는 요청된 할당만큼의 크기 중에서 가장 작은 것을 살펴본다.
최적 할당은 할당 메커니즘의 기본값이다. 할당 비용(CPU)과 힙 파편화 사이에서 괜찮은 트레이드 오프를 갖고 있다.
다음 할당
다음 할당은 미사용 리스트에서 가장 최근의 할당 요청을 만족한 블록에 대한 포인터를 유지한다. 새로운 요청이 들어오면, 이 포인터로부터 미사용 리스트의 끝까지를 살펴보고 그 다음 다시 리스트의 시작으로 돌아와서 이 포인터까지를 살펴본다. 즉, 순환 큐 느낌이다.
다음 할당은 CPU 관점에서 상당히 저렴한 할당 메커니즘이다. 왜냐하면 같은 힙 덩어리를 다 쓸 때까지 할당 요청에서 재사용될 수 있기 때문이다. 이는 곧 CPU 캐시를 더 잘 사용할 수 있는 좋은 메모리 지역성을 갖는다는 뜻이다. 다음 할당의 가장 큰 단점은, 대부분의 할당이 작기 때문에 미사용 리스트의 시작 부분에 있는 큰 블록이 심하게 파편화된다는 점이다.
처음 할당
만약 프로그램이 다양한 크기의 값을 할당한다면, 아마도 미사용 리스트가 파편화되는 것을 목격할 수도 있다. 이런 경우, GC는 미사용 덩어리가 있음에도 불구하고 비싼 연산인 압축을 하게 되는데, 그 어떤 덩어리도 요청을 만족할 만큼 크지 않기 때문이다.
처음 할당은 메모리 파편화를 줄이는데 초점을 맞추고 있다. 즉, 압축의 횟수를 줄인다. 대신, 메모리 할당이 좀더 느리다. 처음 할당 전략의 모든 할당은 미사용 리스트를 처음부터 훑어봐서 적절한 크기의 미사용 덩어리를 찾아내야 한다. 다음 할당처럼 가장 최근의 힙 덩어리를 재사용하지 않는다.
부하가 있는데 더 많은 실시간 동작이 필요한 일부 경우, 힙 압축의 빈도를 감소하는 것이 추가 할당 비용보다 클 수도 있다.
힙 할당 전략 조절
Gc.allocation_policy 필드를 통해 조절할 수 있다.
0: 다음 할당1: 처음 할당2: 최적 할당, 디폴트
또는, OCAMLRUNPARAM에서 a=[0|1|2]로 조절할 수도 있다.
힙 마킹하고 스캔하기
메이저 힙 전체에 대해서 완전히 마킹 작업을 하려면 아주 오랜 시간이 걸릴 수 있고 동작하는 동안 프로그램을 멈춰야 한다. 따라서, 마킹 작업은 점진적으로 동작하며 힙을 조각(slices*으로 나눠서 작업한다. 힙에 있는 각 값은 2비트의 *색깔 필드를 헤더이 갖고 있는데 이걸 이용해서 해당 값의 마킹 여부를 저장하여 GC가 조각 사이를 손쉽게 재시작할 수 있게 해준다.
- 파란색: 현재 미사용 리스트에 있으며 사용 중이 아니다.
- 흰색 (마킹 도중): 루트에서 닿진 않았지만, 닿을 수도 있다.
- 흰색 (스위핑 도중): 루트에서 닿을 수 없고 따라서 해제될 수 있다.
- 검은색: 루트에서 닿을 수 있고 이 값의 모든 필드도 검사되었다.
헤더의 색깔 태그는 마킹 작업의 대부분의 상태를 저장해둬서 작업을 멈췄다가 나중에 다시 시작할 수 있게 해준다. 할당 시에는 모든 힙 값이 흰색으로 초기화되어서 루트에서 닿을 수 있지만 아직 검사되진 않았음을 알린다. GC와 어플리케이션은 번갈아서 메이저 힙의 조각 하나를 마킹하거나 프로그램을 실제로 실행한다. OCaml 런타임은 할당과 가용 메모리 비율에 따라 각각의 메이저 힙 조각 크기를 합리적으로 계산한다.
마킹 작업은 항상 살아있는 루트 값의 집합으로부터 시작한다. 예를 들어 루트 값에는 프로그램 스택이나 글로벌 변수가 있다. 이런 루트 값의 색깔은 검은색이고 마크 스택이라는 특별한 데이터 구조에 추가된다. 마킹은 이 스택에서 값을 하나 꺼내서 그 값의 필드를 검사하면서 진행된다. 흰색 블록을 담고 있는 모든 필드는 검은색으로 바뀌면서 마크 스택에 추가된다.
이 작업은 마크 스택이 비어서 더 이상 마크할 값이 없을 때까지 반복된다. 이 작업에는 한 가지 중요한 엣지 케이스가 있는데, 바로 마크 스택이 특정 크기까지만 자랄 수 있다는 것이다. 그 이후에는 GC가 값의 필드를 따라가는 동안 이걸 저장할 곳이 없어서 더 이상 작업할 수 없다. 이를 마크 스택 오버플로우라고 하며, 이때 가지치기(pruning) 작업이 시작된다. 가지치기는 먼저 마크 스택을 완전히 비우고, 각 블록의 주소를 각 힙 덩어리 헤더의 시작과 끝 범위로 요약한다.
나중에 마킹 작업에서 마크 스택이 비어있으면, 힙을 재까맣게 칠해서(redarkening) 채워넣는다. 이는 재까맣게 칠해야하는 블록, 즉 가지치기 도중에 마크 스택에서 제거된 블록이 있는 첫 번째 주소의 힙 덩어리에서 시작하고, 마크 스택의 1/4만큼이 찰 때까지 재까맣게 칠할 범위로부터 원소를 가져와서 추가한다. 이렇게 가지치기 도중 스택을 비우고 다시 재까맣게 칠해서 채워넣는 순환 작업은 재까맣게 칠할 범위가 남아있는 힙 덩어리가 없을 때까지 계속된다.
메이저 힙 수집 조절
조각 하나를 메이저 GC 하려면 major_slice 함수를 이용할 수 있다. 이
함수는 먼저 마이너 수집을 수행하고 그 다음 한 조각을 수집한다. 조각의
크기는 보통 GC가 자동으로 계산해서 적당한 값을 돌려주는데 나중에 이
크기를 필요한 만큼 조절할 수도 있다.
Gc.major_slice 0;;
Gc.full_major ();;
space_overhead 값을 이용해서 조각 크기를 더 크게 조절하여 GC가 더
공격적으로 동작하게 할 수도 있다. 이 값은 GC가 루트에서 닿을 수 없는
블록을 즉시 수집하지 않아서 “낭비”되는 살아있는 데이터에 사용된
메모리의 비율을 나타낸다. Core 에서는 메모리가 지나치게 제한되지
않는 일반적인 시스템을 어우르기 위해 기본값으로 100을
갖는다. 메모리가 많으면 더 높게 설정해도 되고, 더 낮게 설정하면 CPU
시간을 더 많이 사용하는 대신 GC가 더 열심히 동작하고 블록을 더 빨리
수집할 수 있다.
힙 압축
특정 횟수의 메이저 GC 주기가 완료되고 나면, 힙이 할당된 순서와 다르게 해제되어서 아마 파편화되기 시작할 것이다. 이러면 GC가 새로운 할당을 외해서 연속된 메모리 블록을 찾기 힘들어지고 불필요하게 힙을 많이 먹게 된다.
힙 압축은 메이저 힙에 있는 모든 값을 새로운 힙으로 옮겨서 다시 메모리에서 연속적으로 위치하게끔 해서 이를 피한다. 이 알고리즘을 무지성으로 구현하면 새로운 힙을 위해서 추가적인 메모리가 필요하겠지만, OCaml은 더 똑똑한 알고리즘을 통해 압축을 제자리에서 수행한다.
힙 압축 주기 조절
max_overhead 값은 압축이 시작된 이후 미사용 메모리와 할당된 메모리
사이의 연결을 정의한다.
값이 0이면 모든 메이저 GC 주기가 끝날 때마다 압축을 수행하고, 최대
값인 1_000_000은 힙 압축을 완전히 꺼버린다. 특이한 할당 패턴이 아닌
이상 Core의 기본값인 500으로도 괜찮을 것이다.
세대 사이의 포인터
세대 간 수집의 복잡한 점 중 하나는 마이너 힙 수집이 메이저 힙 수집보다 훨씬 더 자주 일어난다는 사실에서 발생한다. 마이너 힙에 있는 어떤 블록이 살아있는지를 알려면, GC는 메이저 힙 블록이 가리키는 마이너 힙 블록을 따라가야 한다. 이 정보가 없으면 각각의 마이너 수집은 훨씬 큰 메이저 힙을 전부 스캔해야 하는데, 이러면 메이저 수집이나 다를 바 없다.
OCaml은 메이저 힙과 마이너 힙 사이의 의존성을 피하기 위해서 세대 사이의 포인터(inter-generational pointers) 집합을 관리한다. 컴파일러는 메이저 힙 블록이 마이너 힙 블록을 가리키도록 수정될 때마다 소위 기억해둔 집합(remembered set)을 수정하기 위해서 쓰기 배리어(write barrier)를 도입한다.
가변 쓰기 배리어
쓰기 배리어는 코드의 구조에 엄청난 영향을 줄 수 있다. 이는 레코드를 직접 변경하는 것보다 불변 데이터 구조를 이용해서 약간의 변경 사항이 있는 새로운 복사본을 할당하는 게 더 빠를 수 있는 이유 중 하나이다.
OCaml 컴파일러는 모든 가변 타입을 추적해놨다가 이 값이 변경되기 전에
런타임이 caml_modify 함수를 호출하도록 한다. 이 함수는 쓰기 작업
대상의 위치와 변경하려는 값을 확인해서 기억해둔 집합이 일관되도록
보장한다. 쓰기 배리어는 제법 효율적이긴 하지만, 경우에 따라 그냥 빠른
마이너 힙에 새 값을 할당하고 추가적인 마이너 수집을 하는 것보다 느릴
수 있다.
간단한 테스트 프로그램으로 이를 확인해볼 수 있다.
open Core
open Core_bench
type t1 = { mutable iters1: int; mutable count1: float }
type t2 = { iters2: int; count2: float }
let rec test_mutable t1 =
match t1.iters1 with
| 0 -> ()
| _ ->
t1.iters1 <- t1.iters1 - 1;
t1.count1 <- t1.count1 +. 1.0;
test_mutable t1
let rec test_immutable t2 =
match t2.iters2 with
| 0 -> ()
| n ->
let iters2 = n - 1 in
let count2 = t2.count2 +. 1.0 in
test_immutable { iters2; count2 }
let () =
let iters = 1_000_000 in
let tests = [
Bench.Test.create ~name:"mutable" (fun () -> test_mutable { iters1= iters; count1= 0.0 });
Bench.Test.create ~name:"immutable" (fun () -> test_immutable { iters2= iters; count2= 0.0})
] in
Bench.make_command tests |> Command.run
(executable
(name barrier_bench)
(modules barrier_bench)
(libraries core core_bench))
dune exec -- ./barrier_bench.exe -ascii alloc -quota 1
Estimated testing time 2s (2 benchmarks x 1s). Change using '-quota'.
Name Time/Run mWd/Run mjWd/Run Prom/Run Percentage
----------- ---------- --------- ---------- ---------- ------------
mutable 2.86ms 2.00Mw 20.46w 20.46w 100.00%
immutable 2.27ms 5.00Mw 0.15w 0.15w 79.29%
시간/공간 트레이드 오프를 확인할 수 있다. 가변 버전은 불변 버전보다
더 많은 시간을 소모하지만, 더 적은 마이너 힙 워드를 할당한다
(mWd/Run). OCaml의 마이너 할당은 아주 빨라서, (다른 프로그래밍
언어에서) 관용적으로 쓰던 가변 버전보다 불변 데이터 구조를 쓰면 더
좋을 때가 많다. 반면에, 값을 거의 수정하지 않는 경우라면, 그냥 쓰기
배리어를 건드려 가면서 할당을 전혀 하지 않는게 더 빠를 수도 있다.
어떤 패턴이 더 좋을지를 확실하게 알아보는 유일한 방법은 실제 시나리오
상에서 사용자 프로그램을 직접 Core_bench 같은걸 이용해서
벤치마킹하서 트레이드 오프를 실험해보는 것이다. 벤치마크 바이너리는
GC 동작과 관련해서 여러 유용한 옵션을 제공한다.
dune exec -- ./barrier_bench.exe -help
Benchmark for mutable, immutable
barrier_bench.exe [COLUMN ...]
Columns that can be specified are:
time - Number of nano secs taken.
cycles - Number of CPU cycles (RDTSC) taken.
alloc - Allocation of major, minor and promoted words.
gc - Show major and minor collections per 1000 runs.
percentage - Relative execution time as a percentage.
speedup - Relative execution cost as a speedup.
samples - Number of samples collected for profiling.
Columns with no significant values will not be displayed. The
following columns will be displayed by default:
time alloc percentage
Error Estimates
===============
To display error estimates, prefix the column name (or
regression) with a '+'. Example +time.
(1) R^2 is the fraction of the variance of the responder (such as
runtime) that is accounted for by the predictors (such as number of
runs). More informally, it describes how good a fit we're getting,
with R^2 = 1 indicating a perfect fit and R^2 = 0 indicating a
horrible fit. Also see:
http://en.wikipedia.org/wiki/Coefficient_of_determination
(2) Bootstrapping is used to compute 95% confidence intervals
for each estimate.
Because we expect runtime to be very highly correlated with number of
runs, values very close to 1 are typical; an R^2 value for 'time' that
is less than 0.99 should cause some suspicion, and a value less than
0.9 probably indicates either a shortage of data or that the data is
erroneous or peculiar in some way.
Specifying additional regressions
=================================
The builtin in columns encode common analysis that apply to most
functions. Bench allows the user to specify custom analysis to help
understand relationships specific to a particular function using the
flag "-regression" . It is worth noting that this feature requires
some understanding of both linear regression and how various quatities
relate to each other in the OCaml runtime. To specify a regression
one must specify the responder variable and a command separated list
of predictor variables.
For example: +Time:Run,mjGC,Comp
which asks bench to estimate execution time using three predictors
namely the number of runs, major GCs and compaction stats and display
error estimates. Drop the prefix '+' to suppress error estimation. The
variables available for regression include:
Time - Time
Cycls - Cycles
Run - Runs per sampled batch
mGC - Minor Collections
mjGC - Major Collections
Comp - Compactions
mWd - Minor Words
mjWd - Major Words
Prom - Promoted Words
One - Constant predictor for estimating measurement overhead
=== flags ===
[-all-values] Show all column values, including very small ones.
[-ascii] Display data in simple ascii based tables.
[-ci-absolute] Display 95% confidence interval in absolute numbers
[-clear-columns] Don't display default columns. Only show user
specified ones.
[-display STYLE] Table style (short, tall, line, blank or column).
Default short.
[-fork] Fork and run each benchmark in separate child-process
[-geometric SCALE] Use geometric sampling. (default 1.01)
[-linear INCREMENT] Use linear sampling to explore number of runs, example
1.
[-load FILE] ... Analyze previously saved data files and don't run
tests. [-load] can be specified multiple times.
[-no-compactions] Disable GC compactions.
[-overheads] Show measurement overheads, when applicable.
[-quota <INT>x|<SPAN>] Quota allowed per test. May be a number of runs (e.g.
1000x or 1e6x) or a time span (e.g. 10s or 500ms).
Default 10s.
[-reduced-bootstrap] Reduce the number of bootstrapping iterations
[-regression REGR] ... Specify additional regressions (See -? help).
[-save] Save benchmark data to <test name>.txt files.
[-sexp] Output as sexp.
[-stabilize-gc] Stabilize GC between each sample capture.
[-thin-overhead INT] If given, just run the test function(s) N times; skip
measurements and regressions. Float lexemes like "1e6"
are allowed.
[-v] High verbosity level.
[-width WIDTH] width limit on column display (default 200).
[-build-info] print info about this build and exit
[-version] print the version of this build and exit
[-help] print this help text and exit
(alias: -?)
-no-compactions와 -stabilize-gc 옵션을 이용하면 어플리케이션의
메모리가 파편화되는 상황을 강제로 만들 수 있다. 이렇게하면 성능 유닛
테스트에서 이런 상황을 다시 만들기 위해서 그렇게 오래 기다릴 필요
없이 아주 오래 동작하는 어플리케이션을 시뮬레이션할 수 있다.
값에 파이널라이저 붙이기
OCaml의 자동 메모리 관리는 GC 스위핑을 통해서든 프로그램이 끝나든 간에 어떤 값이 더 이상 사용되지 않으면 결국에는 해제되는 것을 보장한다. GC가 값을 해제하기 직전에 추가적인 코드를 실행하는 것이 유용할 때가 있는데, 예를 들면 파일 식별자가 닫혔는지 체크하거나, 아주 긴 로그 메시지가 제대로 기록됐는지를 확인하거나 하는 등이다. 이런 함수를 파이널라이저(finalizer)라고 한다.
어떤 값에 붙일 수 있을까?
힙에 할당되지 않는 다양한 값은 파이널라이저를 붙일 수 없다. 이런
값에는 정수, 상수 생성자, 불리언, 빈 어레이, 빈 리스트, 유닛 값 등이
있다. 어떤 값이 힙에 할당되고 어떤 값은 힙에 할당되지 않는지는 구현에
따라 다른데, 그래서 Core는 Heap_block 모듈을 제공해서
파이널라이저를 붙이기 전에 명시적으로 이를 확인할 수 있다.
어떤 상수 값은 힙에 할당될 수 있지만 프로그램이 살아있는 동안 절대로
해제되지 않는데, 예를 들어 정수 상수의 리스트 등이
있다. Heap_block은 명시적으로 어떤 값이 메이저 힙에 있는지 마이너
힙에 있는지를 확인해주고 대부분의 상수 값에 대해서는 파이널라이저를
붙일 수 없다고 거절한다. 컴파일러 최적화도 역시 배열의 부동소수 값과
같은 몇몇 불변 값을 복제할 수 있다. 이런 값은 프로그램이 다른
복사본을 사용하는 동안 파이널라이즈 될 수도 있다.
이런 이유에서, (1) 힙에 할당된다는 것을 명시적으로 확인한 (2) 가변 값에만 파이널라이저를 붙이는게 좋다. 일반적인 사용법 중 하나는 파일 식별자에다가 파이널라이저를 붙여서 해제를 보장하는 것이다. 하지만, GC가 안쓰는 값을 수집할 때 파이널라이저를 호출하기 때문에, 파이널라이저로 파일 식별자를 닫는 것은 주된 방법이 아니다. 시스템이 바쁘면 GC가 따라잡기도 전에 파일 식별자와 같은 리소스가 쉽게 동날 수 있다.
Core의 Heap_block 모듈을 이용해서 동적으로 특정 값에
파이널라이저를 붙일 수 있는지를 확인하고 나면 그 다음은 Async의
Gc.add_finalizer 함수로 넘어가서 다른 쓰레드에 대해서 안전하게
파이널라이저를 호출하도록 스케쥴링된다.
다음 예시를 통해 어떤 타입이 힙에 할당되는지, 어떤 타입이 컴파일 시점에 상수인지, 여러 타입에 파이널라이저를 붙이는 방법 등을 살펴볼 수 있다.
open Core
open Async
let attach_finalizer n v =
match Heap_block.create v with
| None -> printf "%20s: FAIL\n%!" n
| Some hb ->
let final _ = printf "%20s: OK\n%!" n in
Gc.add_finalizer hb final
type t = { foo: bool }
let main () =
let allocated_float = Unix.gettimeofday () in
let allocated_bool = Float.is_positive allocated_float in
let allocated_string = Bytes.create 4 in
attach_finalizer "immediate int" 1;
attach_finalizer "immediate float" 1.0;
attach_finalizer "immediate variant" (`Foo "hello");
attach_finalizer "immediate string" "hello world";
attach_finalizer "immediate record" {foo = false};
attach_finalizer "allocated bool" allocated_bool;
attach_finalizer "allocated variant" (`Foo allocated_bool);
attach_finalizer "allocated string" allocated_string;
attach_finalizer "allocated record" {foo = allocated_bool};
Gc.compact ();
return ()
let () =
Command.async_spec ~summary:"Testing finalizers"
Command.Spec.empty main
|> Command.run
(executable
(name finalizer)
(modules finalizer)
(libraries core async))
dune exec -- ./finalizer.exe
immediate int: FAIL
immediate float: FAIL
allocated bool: FAIL
allocated record: OK
allocated string: OK
allocated variant: OK
GC가 파이널라이저를 호출하는 순서는 해제되는 순서와 같다. 같은 GC
주기 동안 몇몇 값이 루트에서 닿을 수 없다면, 파이널라이저는
add_finalizer를 호출한 순서의 정반대로 호출될 것이다. 각각의
add_finalizer 호출은 파이널라이저를 추가하여 그 값이 루트에서 닿을
수 없게 되어 수집될 때 호출된다. 원한다면 같은 힙 블록에 여러 개의
파이널라이저를 붙일 수도 있다.
GC 수집 동안 어떤 힙 블록 b가 루트에서 닿을 수 없다고 판단되면,
b에 붙어있는 모든 파이널라이저 함수를 제거해서 순차적으로
호출한다. 따라서, b에 붙어있던 모든 파이널라이저 함수는 딱 한번만
호출된다. 반면, 프로그램이 종료되면 런타임이 끝나기 전에 모든
파이널라이저가 호출되지는 않는다.
파이널라이저에서는 모든 OCaml 기능을 다 사용할 수 있어서, 특정 값을 할당해서 GC되지 않게 하거나 아니면 무한 루프를 돌 수도 있다.