x86 어셈블리 가이드
32비트 x86 어셈블리 언어의 프로그래밍 가이드이다. 전부는 아니고 유용한 서브셋을 다룬다. x86 머신 코드를 생성하는 어셈블리는 몇 가지 종류가 있는데, 여기서는 Microsoft Macro Assembler(MASM) 어셈블러를 다룬다. MASM은 x86 어셈블리 코드를 쓰기 위해서 인텔의 표준 문법을 사용한다.
x86 명령어 전체 셋은 너무 크고 복잡해서 여기서는 다루지 않는다. 인텔의 x86 명령어 셋 매뉴얼은 2900 여 페이지에 달한다. 예를 들면 x86 명령어 셋의 16비트 서브셋이 있는데, 16비트 프로그래밍 모델을 사용하는 일은 꽤 복잡하다. 분할된 메모리 모델을 갖고 있고, 레지스터 사용에 좀더 제약이 많고, 등등. 그래서 여기에서는 x86 프로그래밍의 좀더 현대적인 측면에만 집중해서 x86 프로그래밍에 대해서 기초적인 부분만 다룰려고 한다.
레지스터
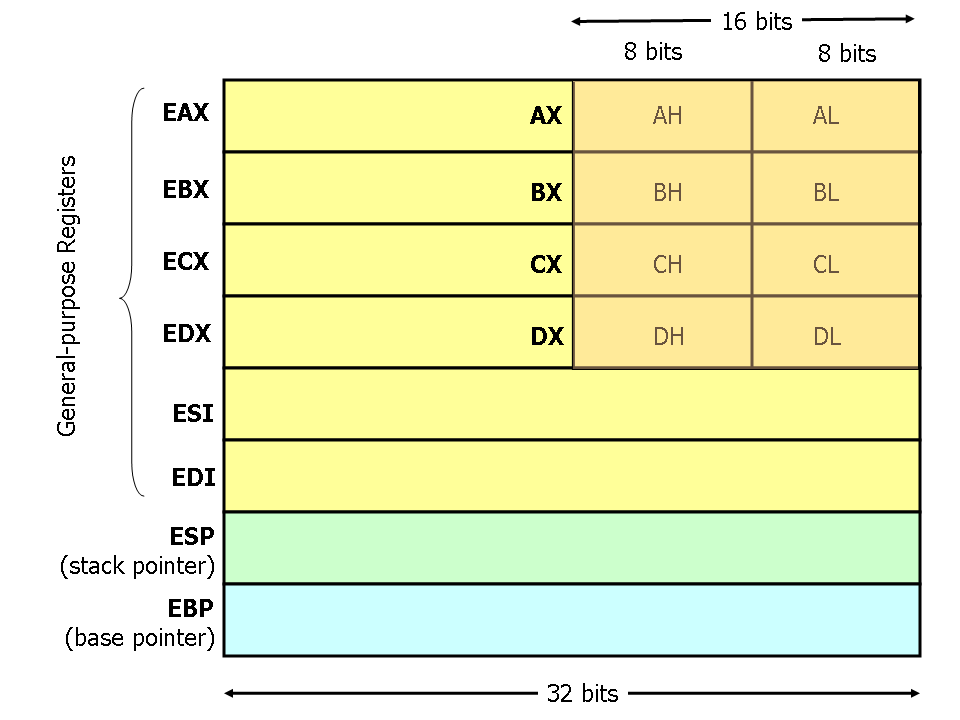
현대적인 (즉, 386 이상) x86 프로세서는 여덟 개의 32비트 범용 목적
레지스터를 갖고 있다. 레지스터의 이름은 주로 역사적인 배경이
있다. 예를 들면, EAX는 Accumulator라고 불렸는데, 왜냐하면 여러
산술 연산에 쓰였기 때문이다. 그리고 ECX는 Counter라고 알려졌는데,
왜냐하면 주로 반복문에 쓰이는 인덱스 값을 갖고 있는데 쓰였기
때문이다. 레지스터의 대부분은 현대적인 명령 셋에서 원래의 특별한
목적을 잃어버린 반면, 관용적으로 딱 두 개의 레지스터는 특별한 목적을
위해 예약되어 있는데 그게 바로 스택 포인터를 위한 ESP와 베이스
포인터를 위한 EBP이다.
EAX, EBX, ECX, 그리고 EDX 레지스터는 일부분만 사용될 수도
있다. 예를 들면, EAX의 LSB 2바이트는 16비트 레지스터 AX로 취급될
수 있다. AX의 LSB 1바이트는 하나의 8비트 레지스터 AL로, AX의
MSB 1바이트는 하나의 8비트 레지스터 AH로 쓰일 수 있다. 이 이름들은
모두 같은 물리적인 레지스터를 가리킨다. 2 바이트의 데이터가 DX에
위치할 때, 이 데이터를 수정하면 DH, DL, EDX 모두에 영향을
미친다. 이런 서브-레지스터는 주로 고대의 16비트 버전 명령 셋을
지원하기 위해서 아직까지 유지되고 있다. 하지만, 32비트보다 작은
1바이트 짜리 아스키 문자를 다루거나 할 때에는 가끔 편리하기도 하다.
어셈블리 언어에서 레지스터를 참조할 때, 이름은 대소문자에 관계
없다. 예를 들면, EAX와 eax는 같은 레지스터를 참조한다.
메모리와 어드레싱 모드
정적 데이터 구역 선언하기
x86 어셈블리에서는 특별한 어셈블러 지시자(directive)를 이용해서 마치
전역 변수와 비슷한 정적 데이터 구역(static data regions)을 선언할
수 있다. 데이터 선언은 .DATA 지시자 앞에 와야 한다. 이 지시자를
따라 DB, DW, 그리고 DD 지시자가 각각 1, 2, 4바이트의 데이터
위치를 선언하는데 사용될 수 있다. 선언된 위치는 나중에 참조할
목적으로 이름으로 레이블링 할 수 있다. 이는 변수를 이름으로 선언하는
것과 비슷하지만, 훨씬 더 저수준의 규칙을 따른다. 예를 들면, 차례차례
선언된 위치는 실제 메모리에서도 차례차례 위치하게 된다.
예시 선언을 보자.
.DATA
var DB 64 ; Declare a byte, referred to as location `var`, containing the value 64.
var2 DB ? ; Declare an uninitialized byte, referred to as location `var2`
DB 10 ; Declare a byte with no label, containing the value 10. Its location is `var2 + 1`
X DW ? ; Declare a 2-byte uninitialized value, referred to as location `X`
Y DD 30000 ; Declare a 4-byte value, referred to as location `Y`, initialized to 30000.
배열이 다차원을 가질 수 있고 인덱스로 접근할 수 있는 고수준의 언어와
다르게, x86 어셈블리 언어의 배열은 단순히 메모리에서 연속적으로
위치한 여러 개의 쎌이다. 배열은 예시처럼 그냥 값을 나열해서 선언할 수
있다. 이 외에 배열을 선언하기 위한 다른 두 개의 일반적인 방법은 DUP
지시자와 문자열 리터럴을 쓰는 것이다. DUP 지시자는 어셈블러가
주어진 횟수만큼 식을 반복하게 해준다. 예를 들면, 4 DUP(2)는 2, 2,
2, 2와 같다.
또 다른 예시를 보자.
Z DD 1, 2, 3 ; Declare three 4-byte values, initialized to 1, 2, and 3. The value of location `Z + 8` will be 3.
bytes DB 10 DUP(?) ; Declare 10 uninitialized bytes starting at location `bytes`
arr DD 100 DUP(0) ; Declare 100 4-byte words starting at location `arr`, all initialized to 0.
str DB 'hello',0 ; Declare 6 bytes starting at the address `str`, initialized to the ASCII character values for `hello` and the null(0) byte.
메모리 주소 지정 (Addressing Memory)
x86과 호환되는 현대 프로세서는 최대 2^32 바이트의 메모리에 대한
주소를 지정할 수 있다: 메모리 주소는 32비트 값이다. 레이블을 이용해서
메모리 구역을 참조한 앞의 예시에서, 이런 레이블은 실제로는 어셈블러에
의해 메모리의 주소를 가리키는 32비트 값으로 바뀐다. 레이블(즉, 상수
값)로 메모리 구역을 참조하는 것이 지원되는 것에 더하여, x86은 메모리
주소를 계산하고 참조하기 위한 유연한 방법을 제공한다. 최대 두 개의
32비트 레지스터와 32비트 부호있는 상수는 메모리 주소를 계산하기
위해서 더해질 수 있다. 또, 레지스터 중 하나는 미리 2, 4, 8 중
하나와 곱해질 수 있다. (정말 저수준이다…)
주소 지정 모드는 많은 x86 명령에 사용될 수 있다. 여기서는 mov
명령으로 레지스터와 메모리 사이에서 데이터를 옮기는 몇 가지 예시를
살펴본다. 이 명령은 두 개의 피연산자를 갖는데, 첫 번째는
목적지(destination)이고 두 번째는 출발지(source)를 명시한다.
다음은 mov 연산으로 주소를 계산하는 예시이다.
mov eax, [ebx] ; Move the 4 bytes in *memory at the address* contained in ebx into eax
mov [var], ebx ; Move the *contents* of ebx into the 4 bytes at memory address `var`. Note, var is a 32-bit constant.
mov eax, [esi-4] ; Move 4 bytes at memory address `esi + (-4)` into eax.
mov [esi+eax], cl ; Move the contents of CL into the byte at address `esi + eax`
mov edx, [esi+4*ebx] ; Move the 4 bytes of data at address esi+4*ebx into edx
다음은 잘못된 주소 계산의 예시이다.
mov eax, [ebx-ecx] ; Can only add register values
mov [eax+esi+edi], ebx ; At most 2 registers in adress computation
사이즈 지시자
일반적으로, 주어진 메모리 주소에서 데이터 아이템의 의도된 사이즈는 참조되는 어셈블리 코드 명령에서 추론할 수 있다. 예를 들어, 모든 위의 예시에서, 메모리 구역의 사이즈는 피연산 레지스터의 크기에서 추론할 수 있다. 32비트 레지스터를 로드할 때, 어셈블러는 참조할 메모리 구역이 4 바이트 크기라는 것을 추론할 수 있다. 1 바이트 레지스터에 담긴 값을 메모리에 저장할 때, 어셈블러는 메모리에서 1 바이트의 주소를 참조하고 싶다는 것을 추론할 수 있다.
하지만, 어떤 경우에는 메모리 구역을 참조하는 사이즈가 모호할 때가
있다. mov [ebx], 2를 생각해보자. 이 명령은 2라는 값을 ebx 주소의
1바이트에 옮겨야 할까? 아마 이 2라는 값은 32비트 정수 표현이라서
ebx 주소의 4바이트에 옮기는 걸지 모른다. 둘 모두 유효한 해석이기
때문에, 어셈블러에게 반드시 명확하게 올바른 방향을 제시해줘야
한다. 사이즈 지시자 BYTE PTR, WORD PTR, DWORD PTR은 이 목적으로
태어났고, 각각 1, 2, 4 바이트의 크기를 알려준다.
mov BYTE PTR [ebx], 2 ; Move 2 into the single byte at the address sotred in ebx.
mov WORD PTR [ebx], 2 ; Move the 16-bit integer representation of 2 into the 2 bytes starting at the address in ebx.
mov DWORD PTR [ebx], 2 ; Move the 32-bit integer representation of 2 into the 4 bytes starting at the address in ebx.
명령
기계 명령은 일반적으로 세 가지 카테고리로 나눠진다: 데이터 이동, 산술/논리, 그리고 제어 흐름이다. 여기서는 각 카테고리의 x86 명령의 아주 중요한 예시를 살펴본다. 여기 있는게 x86 명령의 빠뜨림 없는 목록은 아니고 유용한 서브셋이다. 전체가 궁금하다면 인텔의 명령 셋을 봐라.
다음과 같은 표기법을 사용한다.
<reg32> Any 32-bit register (eax, ebx, ecx, edx, esi, edi, esp, or ebp)
<reg16> Any 16-bit register (ax, bx, cx, or dx)
<reg8> Any 8-bit register (ah, bh, ch, dh, al, bl, cl, or dl)
<reg> Any register
<mem> A memory address (e.g. [eax], [var + 4], or dword ptr [eax+ebx])
<const32> Any 32-bit constant
<const16> Any 16-bit constant
<const8> Any 8-bit constant
<const> Any 8-, 16-, or 32-bit constant
데이터 이동 명령
mov
Opcode: 88, 89, 8A, 8B, 8C, 8E, …
mov 명령은 두 번째 피연산자가 가리키는 데이터 아이템(즉 레지스터의
내용물이나 메모리 내용물, 또는 상수 값)을 첫 번째 피연산자가 가리키는
위치(즉 레지스터나 메모리)에 복사한다. 레지스터에서 레지스터로 값을
복사하는 것은 가능하지만, 메모리에서 곧바로 메모리로 복사하는 것은
불가능하다. 메모리 사이에서 데이터를 옮기고 싶다면, 먼저 옮기려는
대상 메모리 내용물을 레지스터에 로드하고 그 다음 목적지 메모리 주소로
복사해야 한다.
mov <reg>, <reg>
mov <reg>, <mem>
mov <mem>, <reg>
mov <reg>, <const>
mov <mem>, <const>
mov eax, ebx ; Copy the value in ebx into eax
mov byte ptr [var], 5 ; Store the value 5 into the byte at location var
push
Opcode: FF, 89, 8A, 8B, 8C, 8E, …
push 명령은 메모리에서 지원되는 하드웨어 스택에 피연산자를
푸시한다. 구체적으로는, 먼저 esp를 4 만큼 빼고, 그 다음 피연산자를
32비트 위치인 [esp] 주소의 내용물에 옮긴다. 스택 포인터 esp는
푸시를 통해 값이 줄어드는데, 왜냐면 x86 스택이 밑으로 자라기
때문이다. 즉, 높은 주소에서 낮은 주소로 자란다.
push <reg32>
push <mem>
push <const32>
push eax ; Push eax onto the stack
push [var] ; Push the 4 bytes at address var onto the stack
pop
pop 명령은 하드웨어가 지원하는 스택의 꼭대기에서 4 바이트 크기의
데이터 원소를 없애고 피연산자가 명시한 위치(즉, 레지스터 또는 메모리
위치)로 옮긴다. 구체적으로는 먼저 메모리 위치 [esp]에 위치한 4
바이트를 피연산 레지스터 또는 메모리 위치로 옮긴 다음, esp를 4만큼
증가시킨다.
pop <reg32>
pop <mem>
pop edi ; Pop the top element of the stack into edi.
pop [ebx] ; Pop the top element of the stack into memory at the 4-bytes starting at location ebx.
lea - Load Effective Address
lea 명령은 두 번째 피연산자가 명시한 주소를 첫 번째 피연산
레지스터로 옮긴다. 주의할 점은 메모리 위치의 내용물은 로드되지
않고, 오직 유효 주소(effective address)만 계산해서 레지스터로
옮긴다는 점이다. 메모리 구역에 포인터를 얻을 때 유용한 방법이다.
lea <reg32>, <mem>
lea edi, [ebx+4*esi] ; The quantity ebx+4*esi is placed into edi.
lea eax, [var] ; The value in var is placed in eax.
lea eax, [val] ; The value val is placed in eax.
산술과 논리 명령
add - 정수 덧셈
add 명령은 두 개의 피연산자를 더해서 그 결과를 첫 번째 피연산자에
저장한다. 즉, add(a, b) <-> a += b 라고 해석할 수 있다. 피연산자는
둘다 레지스터일 수 있지만, 최대 하나만 메모리 위치일 수 있다.
add <reg>, <reg>
add <reg>, <mem>
add <mem>, <reg>
add <reg>, <const>
add <mem>, <const>
add eax, 10 ; eax += 10
add byte ptr [var], 10 ; Add 10 to the single byte stored at memory address var
sub - 정수 뺄셈
add랑 같은데 뺄셈일 뿐.
sub <reg>, <reg>
sub <reg>, <mem>
sub <mem>, <reg>
sub <reg>, <const>
sub <mem>, <const>
sub al, ah ; al -= ah
sub eax, 216 ; eax -= 216
inc, dec
피연산자의 값을 1만큼 증가시키거나(inc) 감소시키는(dec) 연산이다.
inc <reg>
inc <mem>
dec <reg>
dec <mem>
dec eax ; Subtract one from the contents of eax.
inc dword ptr [var] ; Add one to the 32-bit integer stored at location var
imul - 정수 곱셈
imul 명령은 두 개의 형태를 가지고 있다: 피연산자 두 개 짜리와 세 개
짜리가 있다.
피연산자 두 개 짜리 형태는 이 두 개의 피연산자를 곱해서 첫 번째 피연산자에 저장한다. 이때, 결과를 저장할 첫 번째 피연산자는 반드시 레지스터여야 한다.
피연산자 세 개 짜리 형태는 두 번째와 세 번째 피연산자를 곱해서 첫 번째 피연산자에 저장한다. 여기서도 결과를 저장할 첫 번째 피연산자는 반드시 레지스터여야 한다. 나아가, 세 번째 피연산자는 상수 값만 사용할 수 있다.
imul <reg32>, <reg32>
imul <reg32>, <mem>
imul <reg32>, <reg32>, <const>
imul <reg32>, <mem>, <const>
imul eax, [var] ; Muliply the contents of eax by the 32-bit contents of the memory location var. Store the result in eax.
imul esi, edi, 25 ; esi = edi * 25
idiv - 정수 나눗셈
idiv 명령은 64비트 edx:eax (즉, edx가 MSB가 되고 eax가 LSB가
되는 형태) 에 담긴 정수를 지정된 연산 값(즉, 파라미터)으로
나눈다. 나누기 결과의 몫은 eax에 저장되고 나머지는 edx에
저장된다.
idiv <reg32>
idiv <mem>
idiv ebx ; Divide the contents of edx:eax by the contents of ebx. Place the quotient in eax and the remainder in edx.
idiv dword ptr [var] ; Divice the contents of edx:eax by the 32-bit value stored at memory location var. Place the quotient in eax and the remainder in edx.
and, or, xor - 논리적 비트 연산
논리적 비트 연산을 수행하고 결과를 첫 번째 피연산자에 저장한다.
and|or|xor <reg>, <reg>
and|or|xor <reg>, <mem>
and|or|xor <mem>, <reg>
and|or|xor <reg>, <const>
and|or|xor <mem>, <const>
and eax, 0fH ; Clear all but last 4 bits of eax.
xor edx, edx ; Set the contents of edx to zero.
not
not <reg>
not <mem>
not byte ptr [var] ; Negate all bits in the byte at the memory location var.
neg
2의 보수 연산을 수행한다.
neg <reg>
neg <mem>
neg eax ; eax = -eax
shl, shr - Shift Left, Shift Right
이 연산은 첫 번째 피연산자의 내용물을 왼쪽 또는 오른쪽으로
쉬프트하고, 이로 인해 비게 되는 비트 값을 0으로 채워(padding)
넣는다. 피연산자는 최대 31 위치 만큼 쉬프트될 수 있다. 쉬프트할 수는
두 번째 피연산자로 지정되는데 8비트 상수이거나 cl 레지스터이다. 양
쪽 경우 모두 31 이상 쉬프트되는 경우는 모듈로 32 연산이 수행된다.
shl|shr <reg>, <const8>
shl|shr <mem>, <const8>
shl|shr <reg>, <cl>
shl|shr <reg>, <cl>
shl eax, 1 ; Multiply the value of eax by 2
shr ebx, cl ; Store in ebx the floor of result of dividing the value of ebx by 2^n where n is the value in cl.
제어 흐름 명령
x86 프로세서는 명령 포인터(Instruction Pointer; IP) 레지스터로 지금 명령을 시작할 메모리의 위치가 어딘지를 나타내는 32비트 값을 유지한다. 보통 한 명령이 실행되고 난 이후부터 시작되는 메모리의 다음 명령을 가리키도록 증가된다. IP 레지스터는 직접적으로 다룰 수 없지만, 제어 흐름 명령을 통해 암묵적으로 업데이트할 수는 있다.
<label> 표기법을 이용하면 프로그램 테스트의 특정 위치에
레이블(딱지)를 붙일 수 있다. 레이블은 레이블 이름과 콜론만 있으면 x86
어셈블리 코드 텍스트의 어디든 붙일 수 있다. 예를 들어,
mov esi, [ebp+8]
begin: xor ecx, ecx
mov eax, [esi]
이 코드에서는 둘째 줄의 명령에 begin 레이블이 붙어 있다. 코드의
다른 곳 어디에서든 begin 이라는 편리한 심볼 이름을 이용해서 이
명령이 있는 메모리의 위치를 참조할 수 있다. 즉, 실제로는 32비트 값인
메모리 위치를 대신하여 표현하게 해주는 편리한 방법이 바로 레이블이다.
jmp
프로그램의 제어 흐름을 피연산자가 가리키는 메모리 위치로 이동한다. 간단하게 말해서 이 명령을 만나는 순간 이 명령 이후의 명령이 실행되는 게 아니라 피연산자로 넘겨온 레이블의 위치로 가서 명령을 수행한다.
jmp <label>
jmp begin ; Jump to the instruction labeled begin.
jcondition
j-로 시작하는 이 일련의 명령들은 조건부 점프 연산이다. 이때 조건을
판단하기 위해서 특별한 레지스터인 기계 상태 워드(Machine Status
Word)를 이용하는데, 이 레지스터에 저장된 조건 코드 집합의 상태에
따라 점프한다. 기계 상태 워드의 값은 가장 마지막에 수행된 산술 연산의
정보를 포함한다. 예를 들면, 이 워드의 1비트는 마지막 연산의 결과가
0인지를 나타낸다. 마지막 연산의 결과가 음수인지를 나타내는 비트도
있다. 이런 조건 코드를 근거로, 여러 개의 조건부 점프 연산이 수행될 수
있다. 예를 들면, jz 명령은 마지막 산술 연산의 결과가 0일 때 주어진
레이블로 점프한다. 그렇지 않으면 그냥 그 다음에 오는 명령을 실행할
뿐이다.
여러 개의 조건부 분기 명령은 특별한 비교 명령인 cmp를 수행한 마지막
결과에 따라 직관적으로 이름 지어져 있다. 예를 들면, 조건부 분기 명령
jle와 jne는 먼저 cmp 연산을 수행한 결과가 있어야 동작한다.
je <label> ; jump when equal
jne <label> ; jump when not equal
jz <label> ; jump when the last result was zero
jg <label> ; jump when greater than
jge <label> ; jump when greater than or equal to
jl <label> ; jump when less than
jle <label> ; jump when less than or equal to
cmp eax, ebx
jle done
eax <= ebx이면done레이블로 점프하고, 아니면 다음 연산으로 넘어간다.
cmp - Compare
두 개의 피연산자의 값을 비교하고 그 결과에 따라 기계 상태 워드의
조건 코드를 적절하게 세팅한다. 이 연산은 사실 결과가 버려진다는 점만
제외하면 sub 연산과 동등하다.
cmp <reg>, <reg>
cmp <reg>, <mem>
cmp <mem>, <reg>
cmp <reg>, <const>
cmp dword ptr [var], 10 ; If the 4 bytes stored at location var are equal to the 4-byte integer constant 10,
jeq loop ; then jump to the location labeled loop.
call, ret
이 명령은 서브루틴 호출과 리턴을 구현한다. call 명령은 먼저 현재
코드의 위치를 메모리에 있는 하드웨어 지원 스택에 푸시하고 (위의
push 명령 참조), 그 다음 피연산자 레이블로 무조건적인 점프 명령을
수행한다. 앞에서 봤던 단순한 점프 명령과는 달리, call 명령은
서브루틴을 완료했을 때 돌아올 위치를 저장한다.
ret 명령은 서브루틴 리턴 메커니즘을 구현한다. 이 명령은 먼저
메모리에 있는 하드웨어 지원 스택을 팝해서 (위의 pop 명령 참조) 코드
위치를 꺼내오고 그 다음 이 코드 위치로 무조건적인 점프 명령을
수행한다.
call <label>
ret
호출 규약 (Calling Convention)
드디어 여기까지 왔다. 사실 이거 설명하려고 이 긴 글을 번역하고 있다.
여러 명의 프로그래머가 코드를 공유하고 많은 프로그램에서 쓰일 라이브러리를 개발할 수 있게 하려면, 그리고 일반적으로 서브루틴의 사용을 최대한 간단하게 하려면, 프로그래머는 항상 일반적인 호출 규약을 따라야 한다. 호출 규약은 어떻게 서브루틴을 호출하고 어떻게 리턴할지에 관한 프로토콜이다. 예를 들어, 어떤 호출 규약이 주어지면, 프로그래머는 서브루틴에 파라미터를 어떻게 넘겨줄지 정하기 위해서 서브루틴의 정의를 살펴볼 필요가 없다. 게다가, 호출 규약이 주어지면, 고수준의 프로그래밍 언어 컴파일러는 이런 규칙을 따르도록 코드를 생성할 수 있고 따라서 손으로 작성한 어셈블리 언어의 서브루틴과 고수준 언어의 서브루틴끼리 서로 호출할 수 있게 된다.
실제로는, 많은 호출 규약이 가능하다. 여기서는 가장 널리 쓰이는 C 언어 호출 규약을 살펴본다. 이 규약을 따르면 어셈블리 C와 C++ 코드에서 안전하게 호출할 수 있는 언어 서브루틴을 작성할 수 있고, 또한 어셈블리 언어 코드에서 C 라이브러리 함수를 호출하는 것도 가능해진다.
C 호출 규약은 하드웨어 지원 스택의 사용에 심하게 의존하고 있다. 즉,
push, pop, call, ret 명령에 기반한다. 서브루틴 파라미터는
스택으로 전달된다. 레지스터는 스택에 저장되고, 서브루틴에서 사용하는
지역 변수는 스택 위의 메모리에 위치한다. 대부분의 프로세서 위에서
구현된 아주 많은 고수준 절차적 언어는 이와 유사한 호출 규약을 갖고
있다.
호출 규약은 두 종류의 규칙으로 나눠진다. 하나는 서브루틴을 호출하는 호출자(Caller)가 지켜야 하는 것이고, 다른 하나는 서브루틴을 작성하는 사람(피호출자; Callee)이 지켜야 하는 것이다. 이 규칙을 준수하지 않으면 스택이 엉망인 상태에 빠지기 때문에 프로그램에 중대한 오류가 빠르게 발생한다는 사실을 강조하고 싶다. 따라서, 서브루틴을 작성할 때에는 호출 규약을 지키기 위해서 아주 세심한 주의가 필요하다.
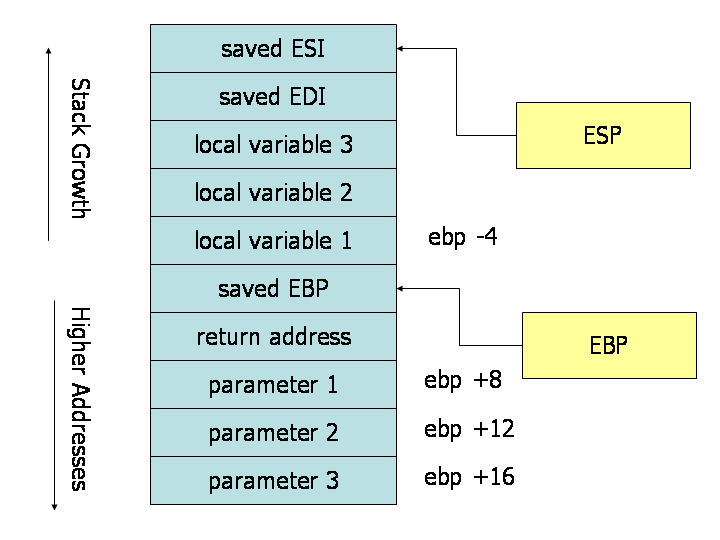
호출 규약을 시각화 하는 좋은 방법은 서브루틴이 실행되는 도중의 스택
영역을 직접 그리는 것이다. 위의 이미지는 세 개의 파라미터와 세 개의
지역 변수가 있는 서브루틴이 실행되는 도중의 스택 상태를 그린
것이다. 스택에 쌓인 각각의 쎌은 32 비트의 메모리 위치이고, 따라서
쎌의 메모리 주소는 4 바이트 씩 떨어져 있다. 첫 번째 파라미터는 베이스
포인터로부터 8 바이트 오프셋만큼 떨어진 곳에 있다. 스택에서
파라미터와 베이스 포인터 사이에는 call 명령이 나중에 돌아올 주소를
푸시해뒀고, 따라서 베이스 포인터에서 첫 번째 파라미터 사이에는
추가적인 4 바이트 오프셋이 존재한다. 서브루틴에서 ret 명령이
호출되면, 여기 저장된 주소로 점프하게 된다.
호출자(콜러) 규칙
서브루틴을 호출하기 위해서, 호출자는 다음을 지켜야 한다:
- 서브루틴을 호출하기 전에, 호출자는 호출자가 저장해야
하는(caller-saved) 특정한 레지스터의 값을 저장해야 한다. 호출자가
저장해야 하는 레지스터에는
eax,ecx,edx가 있다. 호출된 서브루틴이 이런 레지스터를 수정할 수 있기 때문에, 서브루틴이 리턴하고 나서 호출자가 얘네들의 값을 제대로 사용하려면 이 레지스터의 값을 스택에 푸시해둬야 한다. 그래야 서브루틴이 완료되고 나서 다시 값을 복원할 수 있다. - 서브루틴에 파라미터를 전달하기 위해서, 서브루틴을 호출하기 전에 파라미터로 쓰일 값들을 스택에 푸시해야 한다. 이때, 파라미터는 거꾸로 푸시되어야 한다. 즉, 마지막 파라미터를 먼저 푸시해야 한다. 스택이 아래로 자라기 때문에, 첫 번째 파라미터는 가장 낮은 주소에 푸시된다. 이렇게 파라미터가 거꾸로 저장되는 이유는 역사적으로 함수에 가변 갯수의 파라미터를 전달하게 하기 위함이라고 하는데, 정확한건 아직 잘 모르겠음.
- 서브루틴을 호출하려면
call명령을 써야 한다. 이 명령은 스택에서 파라미터 위에다 리턴 주소를 푸시하고 그 다음 서브루틴 코드로 점프한다. 그 이후 호출되는 서브루틴은 피호출자 규칙을 따라야 한다.
서브루틴이 리턴하고 나면, 호출자는 서브루틴의 리턴 값을 eax
레지스터에서 찾으려 할 수 있다. 기계 상태를 복원하기 위해서, 호출자는
또한:
- 스택에서 파라미터를 제거해야 한다. 이를 통해
call명령이 수행되기 전의 스택 상태를 복원한다. - 호출자가 저장해야 하는 레지스터
eax,ecx,edx를 스택에서 팝해서 값을 복원한다. 호출자는 서브루틴에 의해서 수정된 다른 레지스터가 없다고 가정할 수 있다.예시
아래 코드는 호출자 규칙을 따르는 함수 호출을 보여준다. 호출자는 세 개의 정수 파라미터를 받는
_myFunc함수를 호출하고 있다. 첫 번째 파라미터는eax에 있고, 두 번째 파라미터는 상수 216이고, 세 번째 파라미터는 메모리 위치var에 있다.
push [var] ; Push the last parameter first.
push 216 ; Push the second parameter.
push eax ; Push the first parameter last.
call _myFunc ; Call the function (assume C naming).
add esp, 12 ; Clean up the stack after call returns.
함수가 리턴하고 나서 호출자가 add 명령으로 스택을 정리하고 있다는
점을 주목하자. 여기서는 12 바이트, 즉 각각 4 바이트 파라미터 3개를
스택에 쌓았고, 스택은 아래로 자란다. 따라서, 파라미터를 제거하기
위해서, 그냥 스택 포인터에다 12를 더하면 된다.
_myFunc 함수의 결과는 이제 eax 레지스터에서 쓸 수 있다. 호출자가
저장해야 하는 레지스터(ecx, edx)의 값은 아마 바뀌었을 수도
있다. 호출자가 함수 호출 이후 이 레지스터를 쓴다면, 이 값을 스택에
저장해뒀다가 나중에 복원해야 할 필요가 있다.
피호출자(콜리) 규칙
서브루틴의 시작 지점에서 다음과 같은 규칙을 따라야 한다.
- 다음 명령을 따라
ebp의 값을 스택에 푸시하고,esp의 값을ebp에 복사해야 한다.push ebp mov ebp, esp
이 초기화는 베이스 포인터, 즉 ebp를 유지한다. 베이스 포인터는
관용적으로 스택에서 파라미터와 지역 변수를 참조하기 위해서
사용된다. 서브루틴이 실행될 때, 베이스 포인터는 서브루틴이 실행되기
시작했을 때의 스택 포인터 값의 복사본을 갖고 있다. 파라미터와 지역
변수는 항상 어디 위치하고 있는지 알 수 있는데, 베이스 포인터 값에서
상수 오프셋 만큼 차이나는 곳에 위치한다. 서브루틴의 시작 지점에서
옛날 베이스 포인터 값을 푸시해두면 나중에 서브루틴이 리턴했을 때
호출자를 위한 적절한 베이스 포인터 값을 복원할 수 있다. 기억해둘
것은, 호루자는 서브루틴이 베이스 포인터의 값을 바꿀거라고 예상하지
않는다는 점이다. 그러고나서 스택 포인터를 ebp로 복사해서(mov)
파라미터와 지역 변수에 접근하기 위한 적절한 참조 지점을 얻는다.
- 그 다음, 스택에 공간을 만들어서 지역 변수를 할당한다. 스택이
아래로 자라기 때문에, 스택 꼭대기에 공간을 만들려면 스택 포인터가
줄어야 한다는 점을 기억하자. 스택 포인터를 얼마나 줄여야 하는지는
필요한 지역 변수의 갯수와 크기에 달려있다. 예를 들어, 만약 각각 4
바이트 짜리 지역 변수 세 개가 필요하다면, 스택 포인터를 12 만큼
줄여서 (
sub esp, 12)이 지역 변수를 위한 공간을 만들 수 있다. 파라미터와 함께, 지역 변수도 베이스 포인터로부터 상수 오프셋 만큼 떨어진 곳에 위치한다는 것을 알 수 있다. - 그 다음, 함수가 사용하게 될 피호출자가 저장해야
하는(callee-saved) 레지스터의 값을 저장한다. 레지스터를 저장하기
위해서 스택에 푸시하면 된다. 피호출자가 저장해야 하는 레지스터에는
ebx,edi,esi가 있고esp와ebp도 호출 규약에 따르면 보존되어야 하지만 이 과정에서 스택에 푸시될 필요는 없다.
이 세 가지 초기화가 수행되고 나면, 서브루틴의 본문을 수행할 수 있다. 서브루틴이 리턴할 때에는, 반드시 다음 단계를 따라야 한다:
- 리턴 값은
eax에 둔다. - 피호출자가 저장해야 하는 레지스터(
edi,esi)가 수정된 경우 이전 값으로 원복한다. 레지스터 값은 스택에서 팝하여 복원할 수 있다. 레지스터는 푸시된 순서의 반대로 팝되어야 한다. - 지역 변수를 해제한다. 가장 확실한 방법은 스택 포인터에 적절한 값을
더하는 것이다. 왜냐하면 스택 포인터에 적절한 값을 빼서 스택에
필요한 공간을 할당했기 때문이다. 실제로, 오류가 덜 나는 방법은
베이스 포인터의 값을 스택 포인터에다 복사하는 것이다:
mov esp, ebp. 이게 되는 이유는 베이스 포인터는 언제나 지역 변수의 할당 바로 직전의 스택 포인터의 값을 담고 있기 때문이다. - 리턴하기 바로 직전에, 스택에서
ebp를 팝해서 호출자의 베이스 포인터를 복원한다. 서브루틴에 진입하자마자 처음 한 일이 바로 베이스 포인터를 푸시해서 원래 값을 저장한 것이라는 것을 잊지말자. - 마지막으로,
ret명령을 실행해서 호출자의 위치로 리턴한다. 이 명령은 스택에서 적절한 리턴 주소를 찾아서 제거할 것이다.
피호출자의 규칙은 서로 반대되는 두 부분으로 깔끔하게 나뉜다는 사실에 주목하자. 첫 번째 부분은 함수의 시작 지점에 적용되고, 보통 함수의 도입부(Prologue)라고 부른다. 나머지 부분은 함수의 끝 부분에 적용되고, 보통 종결부(Epilogue)라고 부른다.
예시
.486
.MODEL FLAT
.CODE
PUBLIC _myFunc
_myFunc PROC
; Subroutine Prologue
push ebp ; Save the old base pointer value.
mov ebp, esp ; Set the new base pointer value.
sub esp, 4 ; Make room for one 4-byte local variable.
push edi ; Save the values of registers that the funcion will modify.
push esi ; This function uses EDI and ESI
; ( no need to save EBX, EBP, or ESP )
; Subroutine Body
mov eax, [ebp+8] ; Move value of parameter 1 into eax
mov esi, [ebp+12] ; Move value of parameter 2 into esi
mov edi, [ebp+16] ; Move value of parameter 3 into edi
mov [ebp-4], edi ; Move edi into the local variable
add [ebp-4], esi ; Add esi into the local variable
add eax, [ebp-4] ; Add the contents of the local variable into eax (final result)
; Subroutine Epilogue
pop esi ; Recover register values
pop edi
mov esp, ebp ; Deallocate local variables
pop ebp ; Restore the caller's base pointer value
ret
_myFunc ENDP
END
서브루틴의 도입부는 스택 포인터의 스냅샷을 베이스 포인터 ebp에
저장하고, 스택 포인터를 감소시켜서 지역 변수를 할당하고, 스택에
레지스터 값을 저장하는 일련의 표준 작업을 수행하고 있다.
서브루틴의 본문에서 베이스 포인터가 어떻게 쓰이는지 볼 수
있다. 파라미터와 지역 변수 둘 다 서브루틴이 실행되는 동안은 베이스
포인터에서 상수 오프셋만큼 떨어진 곳에 위치하고 있다. 구체적으로,
파라미터는 서브루틴이 호출되기 전에 스택에 쌓이기 때문에, 항상
스택에서 베이스 포인터의 밑에 (즉, 더 높은 주소에)
위치한다. 서브루틴의 첫 번째 파라미터 항상 메모리 위치 ebp + 8에
위치하고, 두 번째는 ebp + 12, 세 번째는 ebp + 16에
위치한다. 비슷하게, 지역 변수는 베이스 포인터가 설정되고 난 이후에
할당되기 때문에, 항상 스택에서 베이스 포인터의 위에 (즉, 더 낮은
주소에) 위치한다. 구체적으로, 첫 번째 지역 변수는 항상 ebp - 4에
위치하고, 두 번째 지역 변수는 ebp - 8에, 등등이다. 이렇게 베이스
포인터를 사용하는 관습은 함수 본문 안에서 지역 변수와 파라미터에
빠르게 접근할 수 있게 해준다.
서브루틴의 종결부는 기본적으로 도입부의 듀얼이다. 호출자의 레지스터
값을 스택에서 복원하고, 스택 포인터를 다시 세팅해서 지역 변수를
해제하고, 호출자의 베이스 포인터 값을 복원하고, ret 명령을 이용해서
호출자의 적절한 코드 위치로 되돌아간다.